arcgis.features.analyze_patterns module¶
These functions help you identify, quantify, and visualize spatial patterns in your data.
calculate_density takes known quantities of some phenomenon and spreads these quantities across the map. find_hot_spots identifies statistically significant clustering in the spatial pattern of your data. interpolate_points predicts values at new locations based on measurements found in a collection of points.
calculate_composite_index¶
-
arcgis.features.analyze_patterns.calculate_composite_index(input_layer, input_variables, index_method=None, output_index_reverse=False, output_index_min_max=None, output_name=None, context=None, gis=None, future=False)¶ The Calculate Composite Index task combines multiple numeric variables to create a single index. This task is only available in ArcGIS Online and Enterprise 11.3+.
Parameter
Description
input_layer
Required layer. The input table or features containing the variables that will be combined into the index.
Syntax: As described in detail in the Feature input topic, this parameter can be one of the following:
A URL to a
feature service layerwith an optional filter to select specific features
#Example #1: Feature Layer with selection >>> output = calculate_composite_index( input_layer= { "url": <feature service layer url>, "filter": <where clause>}, ... ) #Example #2: Feature Collection >>> output = calculate_composite_index( input_layer= {" "layerDefinition": {}, "featureSet": {}, "filter": <where clause>}, ..., )
input_variables
Required list of dictionaries. The variables that will be combined to create the index. Provide at least two variables. For each variable, specify the following:
field is the numeric field from the inputLayer containing the variable. Any records in the field with missing values will not be included in the analysis.
reverseVariable specifies whether the values of the variable will be reversed. If no value is specified, the value will be set to False. When True the feature or record that originally had the highest value will have the lowest value, and vice versa. Values will be reversed after scaling. To create an index, variables must be on a compatible scale; reversing some variables may be required to ensure the meaning of low and high values in each variable is consistent.
weight is the relative influence of the variable on the index. If each variable should have equal contribution, set the value to 1. Increase or decrease the weight to reflect the relative importance of the variable. For example, if a variable is twice as important as the others, use a weight of 2.
#Example: >>> output = calculate_composite_index( ..., input_variables = [ {"field":"median_income", "reverseVariable": True, "weight": 2}, {"field": "pct_uninsured", "reverseVariable": False, "weight": 1}, {"field": "pct_unemployed", "reverseVariable": False, "weight": 1} ], ..., )
index_method
Optional string. The methods that will be used to scale the inputVariables and combine the scaled variables to create the index.
Scaling is a type of preprocessing that ensures the variables are on a compatible scale before they are combined. These scaled variables are then combined to create a single index value. The following options are available:
meanScaled the index by scaling the input variables between 0 and 1 (minimum-maximum scaling) and calculating the mean of the scaled values. This method is useful for creating an index that is easy to interpret. The shape of the distribution and outliers in the input variables will impact the index.
meanPercentile creates the index by scaling the ranks of the input variables between 0 and 1 (scaling by percentile) and calculating the mean of the scaled ranks. This option is useful when the rankings of the variable values are more important than the differences between values. The shape of the distribution and outliers in the input variables will not impact the index.
meanRaw creates the index by calculating the mean of the raw input variables. This option is useful when variables are already on a compatible scale.
geomeanScaled creates the index by scaling the input variables between 0 and 1 (minimum-maximum scaling) and calculating the geometric mean of the scaled values. High values will not cancel low values, so this option is useful for creating an index in which higher index values will occur only when there are high values in multiple variables.
geomeanPercentile creates the index by scaling the ranks of the input variables between 0 and 1 (scaling by percentile) and calculating the geometric mean of the scaled ranks. This option is useful when the rankings of the variable values are more important than the differences between values and when high variable values should not cancel out low variable values.
geomeanRaw creates the index by calculating the geometric mean of the raw input variables. This option is useful when variables are already on a compatible scale and when high variable values should not cancel out low variable values.
sumFlagsPercentile creates the index by counting the number of input variables with values greater than or equal to the 90th percentile. This method is useful for identifying locations that may be considered the most extreme or the most in need.
Values:
meanScaled
meanPercentile
meanRaw
geomeanScaled
geomeanPercentile
geomeanRaw
sumFlagsPercentile
Default: meanScaled
output_index_reverse
Optional boolean. Specifies whether the output index values will be reversed in direction. When checked, high index values will be treated as low index values and vice versa. Reversing is applied after combining the scaled variables. The default is False.
output_index_min_max
Optional list of one dictionary. The minimum and maximum of the output index values. Specifying a minimum and maximum value will apply minimum-maximum scaling to the combined variables.
# Example: >>> output = calculate_composite_index( ..., ouput_index_min_max= [ {'min': 0, 'max': 100} ], ..., )
output_name
Optional dictionary. If provided, the task will create a feature service of the results. You define the name of the service. If no argument is provided, the task will return a feature collection.
# Example #1: >>> output = calculate_composite_index( ..., output_name={ "serviceProperties": { "name": "<service name>" } }, ...
You can overwrite an existing feature service by providing the itemId value of the existing feature service and setting the overwrite property to True. Including the serviceProperties parameter is optional. As described in the Feature output topic, you must either be the owner of the feature service or have administrative privileges to perform the overwrite.
# Example #2: >>> output = calculate_composite_index( ..., ouput_name= { "itemProperties": { "itemId": "<itemID of existing service>", "overwrite": True } }, ) # Example #3: >>> output = calculate_composite_index( ..., ouput_name= { "serviceProperties": { "name": "<existing service name>" }, "itemProperties": { "itemId": "<itemID of the existing feature service>", "overwrite": True } }, ... )
context
Optional dict. The Context parameter contains the following additional settings that affect task operation:
Extent (extent)—A bounding box that defines the analysis area. Only input features that intersect the bounding box will be analyzed.
Output spatial reference (outSR)—The output features will be projected into the output spatial reference.
# Example: >>> output = calculate_composite_index( ..., context= { "extent" : {extent}, "outSR" : {spatial reference} }, ..., )
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.future
Optional boolean. If True, the task will be performed asynchronously.
- Returns
FeatureLayerif output_name is specified, else aFeatureCollectionobject.
# USAGE EXAMPLE: To create a social vulnerability index. index = calculate_composite_index( input_layer=demographicsLayer, input_variables=[ {'field':'pct_uninsured', 'reverseVariable': True, 'weight': 2}, {'field': 'pct_unemployed', 'reverseVariable': False, 'weight': 1} ], index_method='meanPercentile', output_index_reverse=True, output_index_min_max=[ {'min': 0, 'max': 100} ], output_name="Social vulnerability index")
calculate_density¶
-
arcgis.features.analyze_patterns.calculate_density(input_layer, field=None, cell_size=None, cell_size_units='Meters', radius=None, radius_units=None, bounding_polygon_layer=None, area_units=None, classification_type='EqualInterval', num_classes=10, output_name=None, context=None, gis=None, estimate=False, future=False)¶ 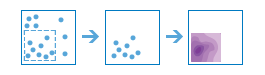
The calculate_density function creates a density map from point or line features by spreading known quantities of some phenomenon (represented as attributes of the points or lines) across the map. The result is a layer of areas classified from least dense to most dense.
For point input, each point should represent the location of some event or incident, and the result layer represents a count of the incident per unit area. A higher density value in a new location means that there are more points near that location. In many cases, the result layer can be interpreted as a risk surface for future events. For example, if the input points represent locations of lightning strikes, the result layer can be interpreted as a risk surface for future lightning strikes.
For line input, the line density surface represents the total amount of line that is near each location. The units of the calculated density values are the length of line per unit area. For example, if the lines represent rivers, the result layer will represent the total length of rivers that are within the search radius. This result can be used to identify areas that are hospitable to grazing animals.
Parameter
Description
input_layer
Required layer. The point or line features from which to calculate density. See Feature Input.
field
Optional string. A numeric field name specifying the number of incidents at each location. For example, if you have points that represent cities, you can use a field representing the population of the city as the count field, and the resulting population density layer will calculate larger population densities near cities with larger populations. If not specified, each location will be assumed to represent a single count.
cell_size
Optional float. This value is used to create a mesh of points where density values are calculated. The default is approximately 1/1000th of the smaller of the width and height of the analysis extent as defined in the context parameter. The smaller the value, the smoother the polygon boundaries will be. Conversely, with larger values, the polygon boundaries will be more coarse and jagged.
cell_size_units
Optional string. The units of the cell_size value. Choice list: [‘Miles’, ‘Feet’, ‘Kilometers’, ‘Meters’]
radius
Optional float. A distance specifying how far to search to find point or line features when calculating density values.
radius_units
Optional string. The units of the radius parameter. If no distance is provided, a default will be calculated that is based on the locations of the input features and the values in the count field (if a count field is provided). Choice list: [‘Miles’, ‘Feet’, ‘Kilometers’, ‘Meters’]
bounding_polygon_layer
Optional layer. A layer specifying the polygon(s) where you want densities to be calculated. For example, if you are interpolating densities of fish within a lake, you can use the boundary of the lake in this parameter and the output will only draw within the boundary of the lake. See Feature Input.
area_units
Optional string. The units of the calculated density values. Choice list: [‘areaUnits’, ‘SquareMiles’]
classification_type
Optional string. Determines how density values will be classified into polygons. Choice list: [‘EqualInterval’, ‘GeometricInterval’, ‘NaturalBreaks’, ‘EqualArea’, ‘StandardDeviation’]
EqualInterval - Polygons are created such that the range of density values is equal for each area.
GeometricInterval - Polygons are based on class intervals that have a geometric series. This method ensures that each class range has approximately the same number of values within each class and that the change between intervals is consistent.
NaturalBreaks - Class intervals for polygons are based on natural groupings of the data. Class break values are identified that best group similar values and that maximize the differences between classes.
EqualArea - Polygons are created such that the size of each area is equal. For example, if the result has more high density values than low density values, more polygons will be created for high densities.
StandardDeviation - Polygons are created based upon the standard deviation of the predicted density values.
num_classes
Optional int. This value is used to divide the range of predicted values into distinct classes. The range of values in each class is determined by the classification_type parameter.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For calculate_density, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional Boolean. Is true, the number of credits needed to run the operation will be returned as a float.
future
Optional, If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
result_layer :
FeatureLayerif output_name is specified, elseFeatureCollection.
If
future = True, then the result is aFutureobject. Callresult()to get the response.USAGE EXAMPLE: To create a layer that shows density of collisions within 2 miles. The density is classified based upon the standard deviation. The range of density values is divided into 5 classes. collision_density = calculate_density(input_layer=collisions, radius=2, radius_units='Miles', bounding_polygon_layer=zoning_lyr, area_units='SquareMiles', classification_type='StandardDeviation', num_classes=5, output_name='density_of_incidents')
find_hot_spots¶
-
arcgis.features.analyze_patterns.find_hot_spots(analysis_layer, analysis_field=None, divided_by_field=None, bounding_polygon_layer=None, aggregation_polygon_layer=None, output_name=None, context=None, gis=None, estimate=False, shape_type=None, cell_size=None, cell_size_unit=None, distance_band=None, distance_band_unit=None, future=False)¶ 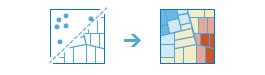
The
find_hot_spotsmethod analyzes point data (such as crime incidents, traffic accidents, or trees) or field values associated with points or area features (such as the number of people in each census tract or the total sales for retail stores). It finds statistically significant spatial clusters of high values (hot spots) and low values (cold spots). For point data when no field is specified, hot spots are locations with lots of points and cold spots are locations with very few points.The result map layer shows hot spots in red and cold spots in blue. The darkest red features indicate the strongest clustering of high values or point densities; you can be 99 percent confident that the clustering associated with these features could not be the result of random chance. Similarly, the darkest blue features are associated with the strongest spatial clustering of low values or the lowest point densities. Features that are beige are not part of a statistically significant cluster; the spatial pattern associated with these features could very likely be the result of random processes and random chance.
Parameter
Description
analysis_layer
Required layer. The point or polygon feature layer for which hot spots will be calculated. See Feature Input.
analysis_field
Optional string. Required if the analysis_layer contains polygons. The numeric field that will be analyzed. The field you select might represent:
counts (such as the number of traffic accidents)
rates (such as the number of crimes per square mile)
averages (such as the mean math test score)
indices (such as a customer satisfaction score)
If an
analysis_fieldis not supplied, hot spot results are based on point densities only.divided_by_field
Optional string. The numeric field in the
analysis_layerthat will be used to normalize your data. For example, if your points represent crimes, dividing by total population would result in an analysis of crimes per capita rather than raw crime counts.You can use esriPopulation to geoenrich each area feature with the most recent population values, which will then be used as the attribute to divide by. This option will use credits.
bounding_polygon_layer
Optional layer. When the analysis layer is points and no
analysis_fieldis specified, you can provide polygons features that define where incidents could have occurred. For example, if you are analyzing boating accidents in a harbor, the outline of the harbor might provide a good boundary for where accidents could occur. When no bounding areas are provided, only locations with at least one point will be included in the analysis. See Feature Input.aggregation_polygon_layer
Optional layer. When the
analysis_layercontains points and noanalysis_fieldis specified, you can provide polygon features into which the points will be aggregated and analyzed, such as administrative units. The number of points that fall within each polygon are counted, and the point count in each polygon is analyzed. See Feature Input.output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For find_hot_spots, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online and ArcGIS Enterprise 11.1+.# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional Boolean. Is true, the number of credits needed to run the operation will be returned as a float.
shape_type
Optional string. The shape of the polygon mesh the input features will be aggregated into.
Fishnet-The input features will be aggregated into a grid of square (fishnet) cells.Hexagon-The input features will be aggregated into a grid of hexagonal cells.
cell_size
Optional float. The size of the grid cells used to aggregate your features. When aggregating into a hexagon grid, this distance is used as the height to construct the hexagon polygons.
cell_size_unit
Optional string. The units of the
cell_sizevalue. You must provide a value ifcell_sizehas been set.Choice list: [‘Meters’, ‘Miles’, ‘Feet’, ‘Kilometers’]
distance_band
Optional float. The spatial extent of the analysis neighborhood. This value determines which features are analyzed together in order to assess local clustering.
distance_band_unit
Optional string. The units of the
distance_bandvalue. You must provide a value ifdistance_bandhas been set.future
Optional, If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
FeatureLayerif output_name is specified, else a dictionary with aFeatureCollectionand processing messages.
If
future = True, then the result is aFutureobject. Callresult()to get the response.USAGE EXAMPLE: To find significant hot ot cold spots of collisions involving a bicycle within a specific boundary. collision_hot_spots = find_hot_spots(collisions, bounding_polygon_layer=boundry_lyr, output_name='collision_hexagon_hot_spots', shape_type='hexagon')
find_outliers¶
-
arcgis.features.analyze_patterns.find_outliers(analysis_layer, analysis_field=None, divided_by_field=None, bounding_polygon_layer=None, aggregation_polygon_layer=None, permutations=None, shape_type=None, cell_size=None, cell_units=None, distance_band=None, band_units=None, output_name=None, context=None, gis=None, estimate=False, future=False)¶ 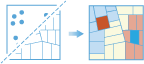
The
find_outliersmethod analyzes point data (such as crime incidents, traffic accidents, or trees) or field values associated with points or area features (such as the number of people in each census tract or the total sales for retail stores). It finds statistically significant spatial clusters of high values and low values and statistically significant high or low spatial outliers within those clusters.The result map layer shows high outliers in red and low outliers in dark blue. Clusters of high values appear pink and clusters of low values appear light blue. Features that are beige are not a statistically significant outlier and not part of a statistically significant cluster; the spatial pattern associated with these features could very likely be the result of random processes and random chance.
Parameter
Description
analysis_layer
Required feature layer. The point or polygon feature layer for which outliers will be calculated. See Feature Input.
analysis_field (Required if the analysis_layer contains polygons)
Optional string. The numeric field that will be analyzed. The field you select might represent:
counts (such as the number of traffic accidents)
rates (such as the number of crimes per square mile)
averages (such as the mean math test score)
indices (such as a customer satisfaction score)
If an
analysis_fieldis not supplied, hot spot results are based on point densities only.divided_by_field
Optional string. The numeric field in the
analysis_layerthat will be used to normalize your data. For example, if your points represent crimes, dividing by total population would result in an analysis of crimes per capita rather than raw crime counts.You can use esriPopulation to geoenrich each area feature with the most recent population values, which will then be used as the attribute to divide by. This option will use credits.
bounding_polygon_layer
Optional layer. When the analysis layer is points and no
analysis_fieldis specified, you can provide polygon features that define where incidents could have occurred. For example, if you are analyzing boating accidents in a harbor, the outline of the harbor might provide a good boundary for where accidents could occur. When no bounding areas are provided, only locations with at least one point will be included in the analysis. See Feature Input.aggregation_polygon_layer
Optional layer. When the
analysis_layercontains points and noanalysis_fieldis specified, you can provide polygon features into which the points will be aggregated and analyzed, such as administrative units. The number of points that fall within each polygon are counted, and the point count in each polygon is analyzed. See Feature Input.permutations
Optional string. Permutations are used to determine how likely it would be to find the actual spatial distribution of the values you are analyzing. Choosing the number of permutations is a balance between precision and increased processing time. A lower number of permutations can be used when first exploring a problem, but it is best practice to increase the permutations to the highest number feasible for final results.
Choice list: [‘Speed’, ‘Balance’, ‘Presision’]
Speed- implements 199 permutations and results in p-values with a precision of 0.005.Balance- implements 499 permutations and results in p-values with a precision of 0.002.Precision- implements 999 permutations and results in p-values with a precision of 0.001.
shape_type
Optional string. The shape of the polygon mesh the input features will be aggregated into.
Fishnet- The input features will be aggregated into a grid of square (fishnet) cells.Hexagon- The input features will be aggregated into a grid of hexagonal cells.
cell_size
Optional float. The size of the grid cells used to aggregate your features. When aggregating into a hexagon grid, this distance is used as the height to construct the hexagon polygons.
cell_units
Optional string. The units of the
cell_sizevalue. You must provide a value ifcell_sizehas been set.Choice list: [‘Meters’, ‘Miles’, ‘Feet’, ‘Kilometers’]
distance_band
Optional float. The spatial extent of the analysis neighborhood. This value determines which features are analyzed together in order to assess local clustering.
band_units
Optional string. The units of the
distance_bandvalue. You must provide a value ifdistance_bandhas been set.Choice list: [‘Meters’, ‘Miles’, ‘Feet’, ‘Kilometers’]
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For find_outliers, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online and ArcGIS Enterprise 11.1+.randomGenerator- A string representing the integer and seed type that will initiate a random number generator. The seed type is always MERSENNE_TWISTER, for example, 13 MERSENNE_TWISTER. This parameter is available in ArcGIS Enterprise 11.2 or later.# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True, "randomGenerator": "13 MERSENNE_TWISTER"}
estimate
Optional boolean. Returns the number of credit for the operation.
future
Optional, If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
FeatureLayerif output_name is set. else results in a dict with the following keys:”find_outliers_result_layer” : layer (
FeatureCollection)”process_info” : list of messages
If
future = True, then the result is aFutureobject. Callresult()to get the response.
#USAGE EXAMPLE: To find statistically significant outliers within the collision clusters. outliers = find_outliers(analysis_layer=collisions, shape_type='fishnet', output_name='find outliers')
find_point_clusters¶
-
arcgis.features.analyze_patterns.find_point_clusters(analysis_layer, min_features_cluster, search_distance=None, search_distance_unit=None, output_name=None, context=None, gis=None, estimate=False, future=False, method=None, sensitivity=None, time_field=None, search_time_interval=None, search_time_unit=None)¶ 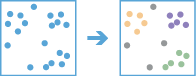
The
find_point_clustersmethod finds clusters of point features within surrounding noise based on their spatial distribution.This method uses unsupervised machine learning clustering algorithms to detect patterns of point features based purely on spatial location and, optionally, the distance to a specified number of features.
The result map shows each cluster identified as well as features considered noise. Multiple clusters will be assigned each color. Colors will be assigned and repeated so that each cluster is visually distinct from its neighboring clusters.
This method uses the DBSCAN, HDBSCAN, or OPTICS method to find clusters. If the method is not specified and the search_distance value is not provided, the HDBSCAN method will be used. If the method is not specified and search_distance value is provided, the DBSCAN algorithm will be used. DBSCAN will use distance, and optionally time, to return clusters with similar densities. It is only appropriate if there is a clear search distance to use for the analysis. HDBSCAN will use a range of distances to separate clusters of varying densities from sparser noise resulting in more data-driven clusters. OPTICS will use the distances, and optionally time, between neighboring features to create a reachability plot, and use it to separate clusters of varying densities from noise.
Parameter
Description
analysis_layer
Required layer. The point feature layer for which density-based clustering will be calculated. See Feature Input.
min_features_cluster
Required integer. The minimum number of features to be considered a cluster. Any cluster with fewer features than the number provided will be considered noise.
search_distance
Optional float. The maximum distance to consider. The Minimum Features per Cluster specified must be found within this distance for cluster membership. Individual clusters will be separated by at least this distance. If a feature is located further than this distance from the next closest feature in the cluster, it will not be included in the cluster.
search_distance_unit
Optional string. The linear unit to be used with the distance value specified for
search_distance. You must provide a value ifsearch_distancehas been set.Choice list: [‘Feet’, ‘Miles’, ‘Meters’, ‘Kilometers’]
The default is ‘Miles’.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For find_point_clusters, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 11+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the GIS on which this tool runs. If not specified, the active GIS is used.
estimate
Optional Boolean. If True, the number of credits to run the operation will be returned.
future
Optional boolean. If True, the result will be a GPJob object and results will be returned asynchronously.
method
Optional string. Specifies the method that will be used to find clusters. If the method is not specified and the search_distance value is not provided, the HDBSCAN algorithm will be used. If the method is not specified and the search_distance value is provided, the DBSCAN algorithm will be used.
This parameter is available in ArcGIS Enterprise 11.2 or higher.
Values: “DBSCAN” | “HDBSCAN” | “OPTICS”
sensitivity
Optional float. A double value between 0 and 100 that determines the compactness of the clusters.
This parameter is available in ArcGIS Enterprise 11.2 or higher.
time_field
Optional string. Specifies the field in the analysis_layer value that contains a timestamp for each feature. This parameter is only available in ArcGIS Online.
Example: time_field = “start_time”
Note
Time related parameters can only be used when the method is DBSCAN or OPTICS.
search_time_interval
Optional float. A value that will be used to determine whether features form a space-time cluster. The search time interval spans before and after the time of each feature. This parameter is only available in ArcGIS Online.
Example: search_time_interval = 4
search_time_unit
Optional string. The unit that will be used with the time value specified for search_time_interval. You must provide a value if search_time_interval has been set. This parameter is only available in ArcGIS Online.
Values: “Seconds” | “Minutes” | “Hours” | “Days” | “Weeks” | “Months” | “Years”
Example: search_time_unit = “Minutes”
- Returns
FeatureLayerifoutput_nameis specified, elseFeatureCollection.
If
future = True, then the result is aFutureobject. Callresult()to get the response.USAGE EXAMPLE: To find patterns of traffic accidents purely on spatial location. clusters= find_point_clusters(collision, min_features_cluster=200, search_distance=2, search_distance_unit='Kilometers', output_name='find point clusters')
interpolate_points¶
-
arcgis.features.analyze_patterns.interpolate_points(input_layer, field, interpolate_option='5', output_prediction_error=False, classification_type='GeometricInterval', num_classes=10, class_breaks=[], bounding_polygon_layer=None, predict_at_point_layer=None, output_name=None, context=None, gis=None, estimate=False, future=False)¶ 
The
interpolate_pointsmethod allows you to predict values at new locations based on measurements from a collection of points. The method takes point data with values at each point and returns areas classified by predicted values. For example:An air quality management district has sensors that measure pollution levels.
interpolate_pointscan be used to predict pollution levels at locations that don’t have sensors, such as locations with at-risk populations, schools, or hospitals, for example.Predict heavy metal concentrations in crops based on samples taken from individual plants.
Predict soil nutrient levels (nitrogen, phosphorus, potassium, and so on) and other indicators (such as electrical conductivity) in order to study their relationships to crop yield and prescribe precise amounts of fertilizer for each location in the field.
Meteorological applications include prediction of temperatures, rainfall, and associated variables (such as acid rain).
interpolate_pointsuses the Empirical Bayesian Kriging geoprocessing tool to perform the interpolation. The parameters that are supplied to the Empirical Bayesian Kriging tool are controlled by theinterpolate_optionrequest parameter.If a value of 1 is provided for
interpolate_option, empirical Bayesian kriging will use the following parameters:transformation_type - NONE
semivariogram_model_type - POWER
max_local_points - 50
overlap_factor - 1
number_semivariograms - 30
nbrMin - 8
nbrMax - 8
If a value of 5 is provided for
interpolate_option, empirical Bayesian kriging will use the following parameters:transformation_type - NONE
semivariogram_model_type - POWER
max_local_points 75
overlap_factor - 1.5
number_semivariograms - 100
nbrMin - 10
nbrMax - 10
If a value of 9 is provided for
interpolate_option, empirical Bayesian kriging will use the following parameters:transformation_type - EMPIRICAL
semivariogram_model_type - K_BESSEL
max_local_points - 200
overlap_factor - 3
number_semivariograms - 200
nbrMin - 15
nbrMax - 15
Parameter
Description
input_layer
Required layer. The point layer whose features will be interpolated. See Feature Input.
field
Required string. Name of the numeric field containing the values you wish to interpolate.
interpolate_option
Optional integer. Integer value declaring your preference for speed versus accuracy, from 1 (fastest) to 9 (most accurate). More accurate predictions take longer to calculate.
Choice list: [1, 5, 9].
The default is 5.
output_prediction_error
Optional boolean. If True, a polygon layer of standard errors for the interpolation predictions will be returned in the
prediction_erroroutput parameter.Standard errors are useful because they provide information about the reliability of the predicted values. A simple rule of thumb is that the true value will fall within two standard errors of the predicted value 95 percent of the time. For example, suppose a new location gets a predicted value of 50 with a standard error of 5. This means that this task’s best guess is that the true value at that location is 50, but it reasonably could be as low as 40 or as high as 60. To calculate this range of reasonable values, multiply the standard error by 2, add this value to the predicted value to get the upper end of the range, and subtract it from the predicted value to get the lower end of the range.
classification_type
Optional string. Determines how predicted values will be classified into areas.
EqualArea- Polygons are created such that the number of data values in each area is equal.
For example, if the data has more large values than small values, more areas will be created for large values.
EqualInterval- Polygons are created such that the range of predicted values is equal for each area.GeometricInterval- Polygons are based on class intervals that have a geometrical series. This method ensures that each class range has approximately the same number of values within each class and that the change between intervals is consistent.Manual- You to define your own range of values for areas. These values will be entered in theclass_breaksparameter below.
Choice list: [‘EqualArea’, ‘EqualInterval’, ‘GeometricInterval’, ‘Manual’]
The default is ‘GeometricInterval’.
num_classes
Optional integer. This value is used to divide the range of interpolated values into distinct classes. The range of values in each class is determined by the
classification_typeparameter. Each class defines the boundaries of the result polygons.The default is 10. The maximum value is 32.
class_breaks
Optional list of floats. If
classification_typeis Manual, supply desired class break values separated by spaces. These values define the upper limit of each class, so the number of classes will equal the number of entered values. Areas will not be created for any locations with predicted values above the largest entered break value. You mst enter at least two values and no more than 32.bounding_polygon_layer
Optional layer. A layer specifying the polygon(s) where you want values to be interpolated. For example, if you are interpolating densities of fish within a lake, you can use the boundary of the lake in this parameter and the output will only contain polygons within the boundary of the lake. See Feature Input.
predict_at_point_layer
Optional layer. An optional layer specifying point locations to calculate prediction values. This allows you to make predictions at specific locations of interest. For example, if the
input_layerrepresents measurements of pollution levels, you can use this parameter to predict the pollution levels of locations with large at-risk populations, such as schools or hospitals. You can then use this information to give recommendations to health officials in those locations.If supplied, the output
predicted_point_layerwill contain predictions at the specified locations. See Feature Input.output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For interpolate_points, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+
# Example Usage >>> context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100, "latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the number of credits to run the operation will be returned.
future
Optional, If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
result_layer :
FeatureLayerifoutput_nameis specified, else Python dictionary with the following keys:”result_layer” : layer (
FeatureCollection)”prediction_error” : layer (
FeatureCollection)”predicted_point_layer” : layer (
FeatureCollection)If
future = True, then the result is aFutureobject. Callresult()to get the response.
#USAGE EXAMPLE: To predict mine production in US at new locations. >>> interpolated = interpolate_points(coal_mines_us, field='Total_Prod', interpolate_option=5, output_prediction_error=True, classification_type='GeometricInterval', num_classes=10, output_name='interpolate coal mines production')