arcgis.features.find_locations module¶
These functions are used to identify areas that meet a number of different criteria you specify. These criteria can be based upon attribute queries (for example, parcels that are vacant) and spatial queries (for example, within 1 kilometer of a river). The areas that are found can be selected from existing features (such as existing land parcels) or new features can be created where all the requirements are met.
find_existing_locations searches for existing areas in a layer that meet a series of criteria. derive_new_locations creates new areas from locations in your study area that meet a series of criteria. find_similar_locations finds locations most similar to one or more reference locations based on criteria you specify. find_centroids finds and generates points from the representative center (centroid) of each input multipoint, line, or area feature. choose_best_facilities choose the best locations for facilities by allocating locations that have demand for these facilities in a way that satisfies a given goal. create_viewshed creates areas that are visible based on locations you specify. create_watersheds creates catchment areas based on locations you specify. trace_downstream determines the flow paths in a downstream direction from the locations you specify
find_existing_locations¶
-
arcgis.features.find_locations.find_existing_locations(input_layers=None, expressions=None, output_name=None, context=None, gis=None, estimate=False, future=False)¶ 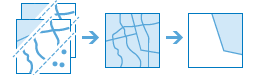
The
find_existing_locationsmethod selects features in the input layer that meet a query you specify. A query is made up of one or more expressions. There are two types of expressions: attribute and spatial. An example of an attribute expression is that a parcel must be vacant, which is an attribute of the Parcels layer (where STATUS = ‘VACANT’). An example of a spatial expression is that the parcel must also be within a certain distance of a river (Parcels within a distance of 0.75 Miles from Rivers).Parameter
Description
input_layers
Required list of feature layers. A list of layers that will be used in the expressions parameter. Each layer in the list can be:
a feature service layer with an optional filter to select specific features, or
a feature collection
See Feature Input.
expressions
Required list of dicts. There are two types of expressions, attribute and spatial.
Example attribute expression:
[{“operator”: “and”,“layer”: 0,“where”: “STATUS = ‘VACANT’”}]Note
operator can be either
andororlayer is the index of the layer in the
input_layersparameter.The where clause must be surrounded by double quotes.
When dealing with text fields, values must be single-quoted (‘VACANT’).
Date fields support all queries except LIKE. Dates are strings in YYYY:MM:DD hh:mm:ss format.
Here’s an example using the date field ObsDate:
“where”: “ObsDate >= ‘1998-04-30 13:30:00’ “
=
Equal
>
Greater than
<
Less than
>=
Greater than or equal to
<=
Less than or equal to
<>
Not equal
LIKE ‘% <string>’
A percent symbol (%) signifies a wildcard, meaning that anything is acceptable in its place-one character, a hundred characters, or no character. This expression would select Mississippi and Missouri among USA state names: STATE_NAME LIKE ‘Miss%’
BETWEEN <value1> AND <value2>
Selects a record if it has a value greater than or equal to <value1> and less than or equal to <value2>. For example, this expression selects all records with an HHSIZE value greater than or equal to 3 and less than or equal to 10:
HHSIZE BETWEEN 3 AND 10
The above is equivalent to:
HHSIZE >= 3 AND HHSIZE <= 10 This operator applies to numeric or date fields. Here is an example of a date query on the field ObsDate:
ObsDate BETWEEN ‘1998-04-30 00:00:00’ AND ‘1998-04-30 23:59:59’
Time is optional.
NOT BETWEEN <value1> AND <value2>
Selects a record if it has a value outside the range between <value1> and less than or equal to <value2>. For example, this expression selects all records whose HHSIZE value is less than 5 and greater than 7.
HHSIZE NOT BETWEEN 5 AND 7
The above is equivalent to:
HHSIZE < 5 OR HHSIZE > 7 This operator applies to numeric or date fields.
Note You can use the
containsrelationship with points and lines. For example, you have a layer of street centerlines (lines) and a layer of manhole covers (points), and you want to find streets that contain a manhole cover. You could usecontainsto find streets that contain manhole covers, but in order for a line to contain a point, the point must be exactly on the line (that is, in GIS terms, they are snapped to each other). If there is any doubt about this, use thewithinDistancerelationship with a suitable distance value.Example spatial expression:
{“operator”: “and”,“layer”: 0,“spatialRel”: “withinDistance”,“selectingLayer”: 1,“distance”: 10,“units”: “miles”}Note
operator can be either
andororlayer is the index of the layer in
the input_layersparameter. The result of the expression is features in this layer.spatialRel is the spatial relationship. There are nine spatial relationships.
distance is the distance to use for the
withinDistanceandnotWithinDistancespatial relationship.units is the units for distance. Units choice list: [‘Meters’, ‘Kilometers’, ‘Feet’, ‘Yards’, ‘Miles’]
An expression may be a list, which denotes a group. The first operator in the group indicates how the group expression is added to the previous expression. Grouping expressions is only necessary when you need to create two or more distinct sets of features from the same layer. One way to think of grouping is that without grouping, you would have to execute
find_existing_locationsmultiple times and merge the results.output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For find_existing_locations, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+
# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional. The
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
FeatureLayerif output_name is specified, elseFeatureCollection.
#USAGE EXAMPLE: To find busy (where SEGMENT_TY is 1 and where ARTERIAL_C is 1) streets from the existing seattle streets layer. arterial_streets = find_existing_locations(input_layers=[bike_route_streets], expressions=[{"operator":"","layer":0,"where":"SEGMENT_TY = 1"}, {"operator":"and","layer":0,"where":"ARTERIAL_C = 1"}], output_name='ArterialStreets')
derive_new_locations¶
-
arcgis.features.find_locations.derive_new_locations(input_layers=[], expressions=[], output_name=None, context=None, gis=None, estimate=False, future=False)¶ 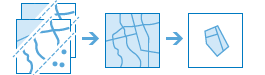
The
derive_new_locationsmethod derives new features from the input layers that meet a query you specify. A query is made up of one or more expressions. There are two types of expressions: attribute and spatial. An example of an attribute expression is that a parcel must be vacant, which is an attribute of the Parcels layer (STATUS = ‘VACANT’). An example of a spatial expression is that the parcel must also be within a certain distance of a river (Parcels within a distance of 0.75 Miles from Rivers).The
derive_new_locationsmethod is very similar to thefind_existing_locationsmethod, the main difference is that the result ofderive_new_locationscan contain partial features.In both methods, the attribute expression
whereand the spatial relationshipswithinandcontainsreturn the same result. This is because these relationships return entire features.When
intersectsorwithin_distanceis used,derive_new_locationscreates new features in the result. For example, when intersecting a parcel feature and a flood zone area that partially overlap each other,find_existing_locationswill return the entire parcel whereasderive_new_locationswill return just the portion of the parcel that is within the flood zone.
Parameter
Description
input_layers
Required list of feature layers. A list of layers that will be used in the expressions parameter. Each layer in the list can be:
a feature service layer with an optional filter to select specific features, or
a feature collection
expressions
Required dict. There are two types of expressions, attribute and spatial.
Example attribute expression:
{“operator”: “and”,“layer”: 0,“where”: “STATUS = ‘VACANT’”}Note
operator can be either
andororlayer is the index of the layer in the
input_layersparameter.The where clause must be surrounded by double quotes.
When dealing with text fields, values must be single-quoted (‘VACANT’).
Date fields support all queries except LIKE. Dates are strings in YYYY:MM:DD hh:mm:ss format. Here’s an example using the date field ObsDate:
“where”: “ObsDate >= ‘1998-04-30 13:30:00’ “
=
Equal
>
Greater than
<
Less than
>=
Greater than or equal to
<=
Less than or equal to
<>
Not equal
LIKE ‘% <string>’
A percent symbol (%) signifies a wildcard, meaning that anything is acceptable in its place-one character, a hundred characters, or no character. This expression would select Mississippi and Missouri among USA state names: STATE_NAME LIKE ‘Miss%’
BETWEEN <value1> AND <value2>
Selects a record if it has a value greater than or equal to <value1> and less than or equal to <value2>. For example, this expression selects all records with an HHSIZE value greater than or equal to 3 and less than or equal to 10:
HHSIZE BETWEEN 3 AND 10
The above is equivalent to:
HHSIZE >= 3 AND HHSIZE <= 10 This operator applies to numeric or date fields. Here is an example of a date query on the field ObsDate:
ObsDate BETWEEN ‘1998-04-30 00:00:00’ AND ‘1998-04-30 23:59:59’
Time is optional.
NOT BETWEEN <value1> AND <value2>
Selects a record if it has a value outside the range between <value1> and less than or equal to <value2>. For example, this expression selects all records whose HHSIZE value is less than 5 and greater than 7.
HHSIZE NOT BETWEEN 5 AND 7
The above is equivalent to:
HHSIZE < 5 OR HHSIZE > 7 This operator applies to numeric or date fields.
You can use the contains relationship with points and lines. For example, you have a layer of street centerlines (lines) and a layer of manhole covers (points), and you want to find streets that contain a manhole cover. You could use contains to find streets that contain manhole covers, but in order for a line to contain a point, the point must be exactly on the line (that is, in GIS terms, they are snapped to each other). If there is any doubt about this, use the withinDistance relationship with a suitable distance value.
Example spatial expression:
{“operator”: “and”,“layer”: 0,“spatialRel”: “withinDistance”,“selectingLayer”: 1,“distance”: 10,“units”: “miles”}operator can be either
andororlayer is the index of the layer in
the input_layersparameter. The result of the expression is features in this layer.spatialRel is the spatial relationship. There are nine spatial relationships.
distance is the distance to use for the
withinDistanceandnotWithinDistancespatial relationship.units is the units for distance. Units choice list: [‘Meters’, ‘Kilometers’, ‘Feet’, ‘Yards’, ‘Miles’]
spatialRel
Description
intersects
notIntersects

A feature in layer passes the intersect test if it overlaps any part of a feature in selectingLayer, including touches (where features share a common point).
intersects - If a feature in layer intersects a feature in selectingLayer, the portion of the feature in layer that intersects the feature in selectingLayer is included in the output.
notintersects - If a feature in layer intersects a feature in selectingLayer, the portion of the feature in layer that intersects the feature in selectingLayer is excluded from the output.
withinDistance
notWithinDistance
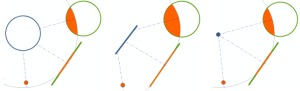
The within a distance relationship uses the straight-line distance between features in layer to those in selectingLayer.
withinDistance - The portion of the feature in layer that is
within the specified distance of a feature in selectingLayer is included in the output. * notwithinDistance - The portion of the feature in layer that is within the specified distance of a feature in selectingLayer is excluded from output. You can think of this relationship as “is farther away than”.
contains
notContains

A feature in layer passes this test if it completely surrounds a feature in selectingLayer. No portion of the containing feature an be outside the containing feature; however, the contained feature is allowed to touch the containing feature (that is, share a common point along its boundary).
contains - If a feature in layer contains a feature in
selectingLayer, the feature in layer is included in the output. * notcontains - If a feature in layer contains a feature in selectingLayer, the feature in the first layer is excluded.
within
notWithin

A feature in layer passes this test if it is completely surrounded by a feature in selectingLayer. The entire feature layer must be within the containing feature; however, the two features are allowed to touch (that is, share a common point along its boundary).
within - If a feature in layer is completely within a feature in selectingLayer, the feature in layer is included in the output.
notwithin - If a feature in layer is completely within a feature in selectingLayer, the feature in layer is excluded from the output.
Note: You can use the within relationship for points and lines, just as you can with the contains relationship. For example, your first layer contains points representing manhole covers and you want to find the manholes that are on street centerlines (as opposed to parking lots or other non-street features). You could use within to find manhole points within street centerlines, but in order for a point to contain a line, the point must be exactly on the line (that is, in GIS terms, they are snapped to each other). If there is any doubt about this, use the withinDistance relationship with a suitable distance value.
| relationship with a suitable distance value. |An expression may be a list, which denotes a group. The first operator in the group indicates how the group expression is added to the previous expression. Grouping expressions is only necessary when you need to create two or more distinct sets of features from the same layer. One way to think of grouping is that without grouping, you would have to execute
derive_new_locationsmultiple times and merge the results.output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For derive_new_locations, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+
# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional. The
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the number of credits needed to run the operation will be returned as a float.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
FeatureLayerif output_name is specified, elseFeatureCollection.
USAGE EXAMPLE: To identify areas that are suitable cougar habitat using the criteria defined by experts. new_location = derive_new_locations(input_layers=[slope, vegetation, streams, highways], expressions=[{"operator":"","layer":0,"selectingLayer":1,"spatialRel":"intersects"}, {"operator":"and","layer":0,"selectingLayer":2,"spatialRel":"withinDistance","distance":500,"units":"Feet"}, {"operator":"and","layer":0,"selectingLayer":3,"spatialRel":"notWithinDistance","distance":1500,"units":"Feet"}, {"operator":"and","layer":0,"where":"GRIDCODE = 1"}], output_name='derive_new_locations')
find_similar_locations¶
-
arcgis.features.find_locations.find_similar_locations(input_layer, search_layer, analysis_fields=None, input_query=None, number_of_results=0, output_name=None, context=None, gis=None, estimate=False, future=False, criteria_fields=None)¶ 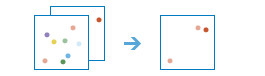
The
find_similar_locationsmethod measures the similarity of candidate locations to one or more reference locations.Based on criteria you specify,
find_similar_locationscan answer questions such as the following:Which of your stores are most similar to your top performers with regard to customer profiles?
Based on characteristics of villages hardest hit by the disease, which other villages are high risk?
To answer questions such as these, you provide the reference locations (the
input_layerparameter), the candidate locations (thesearch_layerparameter), and the fields representing the criteria you want to match. For example, theinput_layermight be a layer containing your top performing stores or the villages hardest hit by the disease. Thesearch_layercontains your candidate locations to search. This might be all of your stores or all other villages. Finally, you supply a list of fields to use for measuring similarity.find_similar_locationswill rank all of the candidate locations by how closely they match your reference locations across all of the fields you have selected.Parameter
Description
input_layer
Required feature layer. The
input_layercontains one or more reference locations against which features in thesearch_layerwill be evaluated for similarity. For example, theinput_layermight contain your top performing stores or the villages hardest hit by a disease. It is not uncommon that theinput_layerandsearch_layerare the same feature service. For example, the feature service contains locations of all stores, one of which is your top performing store. If you want to rank the remaining stores from most to least similar to your top performing store, you can provide a filter for both the inputLayer and thesearch_layer. The filter on theinput_layerwould select the top performing store while the filter on thesearch_layerwould select all stores except for the top performing store. You can also use the optionalinput_queryparameter to specify reference locations.If there is more than one reference location, similarity will be based on averages for the fields you specify in the
analysis_fieldsparameter. So, for example, if there are two reference locations and you are interested in matching population, the task will look for candidate locations in thesearch_layerwith populations that are most like the average population for both reference locations. If the values for the reference locations are 100 and 102, for example, the method will look for candidate locations with populations near 101. Consequently, you will want to use fields for the reference locations fields that have similar values. If, for example, the population values for one reference location is 100 and the other is 100,000, the tool will look for candidate locations with population values near the average of those two values: 50,050. Notice that this averaged value is nothing like the population for either of the reference locations. See Feature Input.search_layer
Required feature layer. The layer containing candidate locations that will be evaluated against the reference locations. See Feature Input.
analysis_fields
Optional list of strings. A list of fields whose values are used to determine similarity. They must be numeric fields and the fields must exist on both the
input_layerand thesearch_layer. The method will find features in thesearch_layerthat have field values closest to those of the features in yourinput_layer.input_query
Optional string. In the situation where the
input_layerand thesearch_layerare the same feature service, this parameter allows you to input a query on theinput_layerto specify which features are the reference locations. The reference locations specified by this query will not be analyzed as candidates. The syntax ofinput_queryis the same as a filter.number_of_results
Optional int. The number of ranked candidate locations output to the
similar_result_layer. Ifnumber_of_resultsis not specified, or set to zero, all candidate locations will be ranked and output.output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For find_similar_locations, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online and ArcGIS Enterprise 11.1+.
# Example Usage >>> locations_output = find_similar_locations( ... context = { "extent": { "xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{ "wkid":102100, "latestWkid":3857} }, "outSR": {"wkid": 3857}, "overwrite": True} ... )
gis
Optional. The
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the number of credits to run the operation will be returned.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
criteria_fields
Optional list of dicts. The fields in the inputLayer value that correspond to the fields in the search_layer value that will be used to determine similarity. All fields must be numeric fields. The task will rank the features in the search_layer value based on the similarity of their field values to the corresponding field values in the input_layer value. Either an analysis_fields or criteria_fields value must be provided.
This parameter is available in ArcGIS Enterprise 11.2 or higher.
Examples:
[{“referenceField”:”population”, “candidateField”:”pop”}] # (single criteria field)
- [
{“referenceField”:”population”, “candidateField”:” pop”}, {“referenceField”:”age”, “candidateField”:”age”}, {“referenceField”:”edu”, “candidateField”:”education”}
] # (multiple criteria field)
- Returns
FeatureLayerifoutput_nameis specified, else Python dictionary with the following keys:similar_result_layer :
FeatureCollectionprocess_info : list of messages
#USAGE EXAMPLE: To find top 4 most locations from the candidates layer that are similar to the target location. >>> top_4_most_similar_locations = find_similar_locations( target_lyr, candidates_lyr, analysis_fields=['THH17','THH35','THH02','THH05','POPDENS14','FAMGRW10_14','UNEMPRT_CY'], output_name = "top 4 similar locations", number_of_results=4 )
find_centroids¶
-
arcgis.features.find_locations.find_centroids(input_layer, point_location=False, output_name=None, context=None, gis=None, estimate=False, future=False)¶ 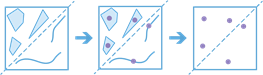
The
find_centroidsmethod that finds and generates points from the representative center (centroid) of each input multipoint, line, or polygon feature. Finding the centroid of a feature is very common for many analytical workflows where the resulting points can then be used in other analytic workflows.For example, polygon features that contain demographic data can be converted to centroids that can be used in network analysis.
Parameter
Description
input_layer
Required feature layer. The multipoint, line, or polygon features that will be used to generate centroid point features. See Feature Input.
point_location
Optional boolean. A Boolean value that determines the output location of the points.
True - Output points will be the nearest point to the actual centroid, but located inside or contained by the bounds of the input feature.
False - Output point locations will be determined by the calculated geometric center of each input feature. This is the default.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service.If overwrite is True in *contextI, new layer will overwrite existing layer.
If output_name not provided, a new
FeatureCollectionis created.
context
Optional dict. Additional settings such as processing extent and output spatial reference. For find_centroids, there are three context settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+.
# Example Usage centroids_res = find_centroids( ... context = { "extent": { "xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{ "wkid":102100, "latestWkid":3857 } }, "outSR": {"wkid": 3857}, "overwrite": True } ... )
gis
Optional. The
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the number of credits to run the operation will be returned.
future
Optional boolean.
If True, a future object will be returned which can be queried for results. The process will return control to user.
If False, the process completes before returning control to the user. The default is False.
- Returns
FeatureLayerifoutput_nameis specifiedFeatureCollectionifoutput_namenot specified
# USAGE EXAMPLE: To find centroids of madison fields nearest to the actual centroids. centroid = find_centroids(madison_fields, point_location=True, output_name='find centroids')
choose_best_facilities¶
-
arcgis.features.find_locations.choose_best_facilities(goal='Allocate', demand_locations_layer=None, demand=1, demand_field=None, max_travel_range=2147483647, max_travel_range_field=None, max_travel_range_units='Minutes', travel_mode=None, time_of_day=None, time_zone_for_time_of_day='GeoLocal', travel_direction='FacilityToDemand', required_facilities_layer=None, required_facilities_capacity=2147483647, required_facilities_capacity_field=None, candidate_facilities_layer=None, candidate_count=1, candidate_facilities_capacity=2147483647, candidate_facilities_capacity_field=None, percent_demand_coverage=100, output_name=None, context=None, gis=None, estimate=False, point_barrier_layer=None, line_barrier_layer=None, polygon_barrier_layer=None, future=False)¶ 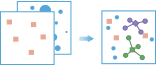
The
choose_best_facilitiesmethod finds the set of facilities that will best serve demand from surrounding areas.Facilities might be public institutions that offer a service, such as fire stations, schools, or libraries, or they might be commercial ones such as drug stores or distribution centers for a parcel delivery service. Demand represents the need for a service that the facilities can meet. Demand is associated with point locations, with each location representing a given amount of demand.
Parameter
Description
goal
Optional string. Specify the goal that must be satisfied when allocating demand locations to facilities.
Choice list: [‘Allocate’, ‘MinimizeImpedance’, ‘MaximizeCoverage’, ‘MaximizeCapacitatedCoverage’, ‘PercentCoverage’]
Default value is ‘Allocate’.
demand_locations_layer
Required point feature layer. A point layer specifying the locations that have demand for facilities. See Feature Input.
demand
Optional float. The amount of demand available at every demand locations.
The default value is 1.0.
demand_field
Optional string. A numeric field on the
demand_locations_layerrepresenting the amount of demand available at each demand location. If specified, thedemandparameter is ignored.max_travel_range
Optional float. Specify the maximum travel time or distance allowed between a demand location and the facility it is allocated to.
The default is unlimited (2,147,483,647.0).
max_travel_range_field
Optional string. A numeric field on the
demand_locations_layerspecifying the maximum travel time or distance allowed between a demand location and the facility it is allocated to. If specified, themax_travel_rangeparameter is ignored.max_travel_range_units
Optional string. The units for the maximum travel time or distance allowed between a demand location and the facility it is allocated to.
Choice list: [‘Seconds’, ‘Minutes’, ‘Hours’, ‘Days’, ‘Meters’, ‘Kilometers’, ‘Feet’, ‘Yards’, ‘Miles’].
The default is ‘Minutes’.
travel_mode
Specify the mode of transportation for the analysis.
Choice list: [‘Driving Distance’, ‘Driving Time’, ‘Rural Driving Distance’, ‘Rural Driving Time’, ‘Trucking Distance’, ‘Trucking Time’, ‘Walking Distance’, ‘Walking Time’]
time_of_day
Optional datetime.datetime. Specify whether travel times should consider traffic conditions. To use traffic in the analysis, set travel_mode to a travel mode object whose impedance_attribute_name property is set to travel_time and assign a value to time_of_day. (A travel mode with other impedance_attribute_name values don’t support traffic.) The
time_of_dayvalue represents the time at which travel begins, or departs, from the origin points. The time is specified as datetime.datetime.The service supports two kinds of traffic: ty pical and live. Typical traffic references travel speeds that are made up of historical averages for each five-minute interval spanning a week. Live traffic retrieves speeds from a traffic feed that processes phone probe records, sensors, and other data sources to record actual travel speeds and predict speeds for the near future.
The data coverage page shows the countries Esri currently provides traffic data for.
Typical Traffic:
To ensure the task uses typical traffic in locations where it is available, choose a time and day of the week, and then convert the day of the week to one of the following dates from 1990:
Monday - 1/1/1990
Tuesday - 1/2/1990
Wednesday - 1/3/1990
Thursday - 1/4/1990
Friday - 1/5/1990
Saturday - 1/6/1990
Sunday - 1/7/1990
Set the time and date as datetime.datetime.
For example, to solve for 1:03 p.m. on Thursdays, set the time and date to 1:03 p.m., 4 January 1990; and convert to datetime eg. datetime.datetime(1990, 1, 4, 1, 3).
Live Traffic:
To use live traffic when and where it is available, choose a time and date and convert to datetime.
Esri saves live traffic data for 4 hours and references predictive data extending 4 hours into the future. If the time and date you specify for this parameter is outside the 24-hour time window, or the travel time in the analysis continues past the predictive data window, the task falls back to typical traffic speeds.
Examples: from datetime import datetime
“time_of_day”: datetime(1990, 1, 4, 1, 3) # 13:03, 4 January 1990. Typical traffic on Thursdays at 1:03 p.m.
“time_of_day”: datetime(1990, 1, 7, 17, 0) # 17:00, 7 January 1990. Typical traffic on Sundays at 5:00 p.m.
“time_of_day”: datetime(2014, 10, 22, 8, 0) # 8:00, 22 October 2014. If the current time is between 8:00 p.m., 21 Oct. 2014 and 8:00 p.m., 22 Oct. 2014, live traffic speeds are referenced in the analysis; otherwise, typical traffic speeds are referenced.
“time_of_day”: datetime(2015, 3, 18, 10, 20) # 10:20, 18 March 2015. If the current time is between 10:20 p.m., 17 Mar. 2015 and 10:20 p.m., 18 Mar. 2015, live traffic speeds are referenced in the analysis; otherwise, typical traffic speeds are referenced.
time_zone_for_time_of_day
Optional string. Specify the time zone or zones of the time_of_day parameter.
Choice list: [‘GeoLocal’, ‘UTC’]
GeoLocal-refers to the time zone in which the origins_layer points are located.
UTC-refers to Coordinated Universal Time.
travel_direction
Optional string. Specify whether to measure travel times or distances from facilities to demand locations or from demand locations to facilities.
Choice list: [‘FacilityToDemand’, ‘DemandToFacility’]
required_facilities_layer
Optional point feature layer. A point layer specifying one or more locations that act as facilities by providing some kind of service. Facilities specified by this parameter are required to be part of the output solution and will be used before any facilities from the
candidate_facilities_layerwhen allocating demand locations.required_facilities_capacity
Optional float. Specify how much demand every facility in the
required_facilities_layeris capable of supplying.The default value is unlimited (2,147,483,647).
required_facilities_capacity_field
Optional string. A field on the required_facilities_layer representing how much demand each facility in the
required_facilities_layeris capable of supplying. This parameter takes precedence whenrequired_facilities_capacityparameter is also specified.candidate_facilities_layer
Optional point layer. A point layer specifying one or more locations that act as facilities by providing some kind of service. Facilities specified by this parameter are not required to be part of the output solution and will be used only after all the facilities from the
candidate_facilities_layerhave been used when allocating demand locations.candidate_count
Optional integer. The number of candidate facilities to choose when allocating demand locations. Note that the sum of the features in the
required_facilities_capacityand the value specified forcandidate_countcannot exceed 100.The default value is 1.
candidate_facilities_capacity
Optional float. Specify how much demand every facility in the
candidate_facilities_layeris capable of supplying.The default value is unlimited (2,147,483,647.0).
candidate_facilities_capacity_field
Optional string. A field on the
candidate_facilities_layerrepresenting how much demand each facility in thecandidate_facilities_layeris capable of supplying. This parameter takes precedence whencandidate_facilities_capacityparameter is also specified.percent_demand_coverage
Optional float. Specify the percentage of the total demand that you want the chosen and required facilities to capture.
The default value is 100.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For choose_best_facilities, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional. The
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. Is true, the number of credits needed to run the operation will be returned as a float.
point_barrier_layer
Optional layer. Specify one or more point features that act as temporary restrictions (in other words, barriers) when traveling on the underlying streets.
A point barrier can model a fallen tree, an accident, a downed electrical line, or anything that completely blocks traffic at a specific position along the street. Travel is permitted on the street but not through the barrier. See Feature Input.
line_barrier_layer
Optional layer. Specify one or more line features that prohibit travel anywhere the lines intersect the streets.
A line barrier prohibits travel anywhere the barrier intersects the streets. For example, a parade or protest that blocks traffic across several street segments can be modeled with a line barrier. See Feature Input.
polygon_barrier_layer
Optional layer. Specify one or more polygon features that completely restrict travel on the streets intersected by the polygons.
One use of this type of barrier is to model floods covering areas of the street network and making road travel there impossible. See Feature Input.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
When an output_name is specified, a
FeatureCollectionwith 3 layers is returned (see dictionary below for details), else a dict with the following keys:”allocated_demand_locations_layer” : layer (
FeatureCollection)”allocation_lines_layer” : layer (
FeatureCollection)”assigned_facilities_layer” : layer (
FeatureCollection)
USAGE EXAMPLE: To minimize overall distance travelled for travelling from esri offices to glider airports. best_facility = choose_best_facilities(goal="MinimizeImpedance", demand_locations_layer=esri_offices, travel_mode='Driving Distance', travel_direction="DemandToFacility", required_facilities_layer=gliderport_lyr, candidate_facilities_layer=balloonport_lyr, candidate_count=1, output_name="choose best facilities")
create_viewshed¶
-
arcgis.features.find_locations.create_viewshed(input_layer, dem_resolution='Finest', maximum_distance=None, max_distance_units='Meters', observer_height=None, observer_height_units='Meters', target_height=None, target_height_units='Meters', generalize=True, output_name=None, context=None, gis=None, estimate=False, future=False)¶ 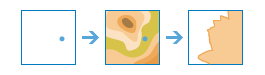
The create_viewshed method identifies visible areas based on the observer locations you provide. The results are areas where the observers can see the observed objects (and the observed objects can see the observers).
Parameter
Description
input_layer
Required point feature layer. The features to use as the observer locations. See Feature Input.
dem_resolution
Optional string. The approximate spatial resolution (cell size) of the source elevation data used for the calculation.
The resolution values are an approximation of the spatial resolution of the digital elevation model. While many elevation sources are distributed in units of arc seconds, the keyword is an approximation of those resolutions in meters for easier understanding.
Choice list: [‘FINEST’, ‘10m’, ‘24m’, ‘30m’, ‘90m’]
The default is the finest resolution available.
maximum_distance
Optional float. This is a cutoff distance where the computation of visible areas stops. Beyond this distance, it is unknown whether the analysis points and the other objects can see each other.
It is useful for modeling current weather conditions or a given time of day, such as dusk. Large values increase computation time.
Unless specified, a default maximum distance will be computed based on the resolution and extent of the source DEM. The allowed maximum value is 50 kilometers. Use max_distance_units to set the units for maximum_distance.
max_distance_units
Optional string. The units for the maximum_distance parameter.
Choice list: [‘Meters’, ‘Kilometers’, ‘Feet’, ‘Miles’, ‘Yards’]
The default is ‘Meters’.
observer_height
Optional float. This is the height above the ground of the observer locations.
The default is 1.75 meters, which is approximately the average height of a person. If you are looking from an elevated location, such as an observation tower or a tall building, use that height instead.
Use observer_height_units to set the units for observer_height.
observer_height_units
Optional string. The units for the observer_height parameter.
Choice list: [‘Meters’, ‘Kilometers’, ‘Feet’, ‘Miles’, ‘Yards’]
The default is ‘Meters’.
target_height
Optional float. This is the height of structures or people on the ground used to establish visibility. The result viewshed are those areas where an input point can see these other objects. The converse is also true; the other objects can see an input point.
If your input points represent wind turbines and you want to determine where people standing on the ground can see the turbines, enter the average height of a person (approximately 6 feet). The result is those areas where a person standing on the ground can see the wind turbines.
If your input points represent fire lookout towers and you want to determine which lookout towers can see a smoke plume 20 feet high or higher, enter 20 feet for the height. The result is those areas where a fire lookout tower can see a smoke plume at least 20 feet high.
If your input points represent scenic overlooks along roads and trails and you want to determine where wind turbines 400 feet high or higher can be seen, enter 400 feet for the height. The result is those areas where a person standing at a scenic overlook can see a wind turbine at least 400 feet high.
If your input points represent scenic overlooks and you want to determine how much area on the ground people standing at the overlook can see, enter zero. The result is those areas that can be seen from the scenic overlook.
Use target_height_units to set the units for target_height.
target_height_units
Optional string. The units for the target_height parameter.
Choice list: [‘Meters’, ‘Kilometers’, ‘Feet’, ‘Miles’, ‘Yards’]
The default is ‘Meters’.
generalize
Optional boolean. Determines whether or not the viewshed polygons are to be generalized.
The viewshed calculation is based on a raster elevation model that creates a result with stair-stepped edges. To create a more pleasing appearance and improve performance, the default behavior is to generalize the polygons. The generalization process smooths the boundary of the visible areas and may remove some single-cell visible areas.
The default value is True.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For create_viewshed, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional. The
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the estimated number of credits required to run the operation will be returned.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
result_layer :
FeatureLayerif output_name is specified, elseFeatureCollection.
USAGE EXAMPLE: To create viewshed around esri headquarter office. viewshed3 = create_viewshed(hq_lyr, maximum_distance=9, max_distance_units='Miles', target_height=6, target_height_units='Feet', output_name="create Viewshed")
create_watersheds¶
-
arcgis.features.find_locations.create_watersheds(input_layer, search_distance=None, search_units='Meters', source_database='FINEST', generalize=True, output_name=None, context=None, gis=None, estimate=False, future=False)¶ 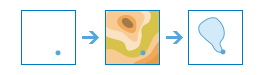
The
create_watershedsmethod determines the watershed, or upstream contributing area, for each point in your analysis layer. For example, suppose you have point features representing locations of waterborne contamination, and you want to find the likely sources of the contamination. Since the source of the contamination must be somewhere within the watershed upstream of the point, you would use this tool to define the watersheds containing the sources of the contaminant.Parameter
Description
input_layer
Required point feature layer. The point features used for calculating watersheds. These are referred to as pour points, because it is the location at which water pours out of the watershed. See Feature Input.
search_distance
Optional float. The maximum distance to move the location of an input point. Use search_units to set the units for search_distance.
If your input points are located away from a drainage line, the resulting watersheds are likely to be very small and not of much use in determining the upstream source of contamination. In most cases, you want your input points to snap to the nearest drainage line in order to find the watersheds that flows to a point located on the drainage line. To find the closest drainage line, specify a search distance. If you do not specify a search distance, the tool will compute and use a conservative search distance.
To use the exact location of your input point, specify a search distance of zero.
For analysis purposes, drainage lines have been precomputed by Esri using standard hydrologic models. If there is no drainage line within the search distance, the location containing the highest flow accumulation within the search distance is used.
search_units
Optional string. The linear units specified for the search distance.
Choice list: [‘Meters’, ‘Kilometers’, ‘Feet’, ‘Miles’, ‘Yards’]
source_database
Optional string. Keyword indicating the data source resolution that will be used in the analysis.
Choice list: [‘Finest’, ‘30m’, ‘90m’]
Finest (Default): Finest resolution available at each location from all possible data sources.
30m: The hydrologic source was built from 1 arc second - approximately 30 meter resolution, elevation data.
90m: The hydrologic source was built from 3 arc second - approximately 90 meter resolution, elevation data.
generalize
Optional boolean. Determines if the output watersheds will be smoothed into simpler shapes or conform to the cell edges of the original DEM.
True: The polygons will be smoothed into simpler shapes. This is the default.
False: The edge of the polygons will conform to the edges of the original DEM.
The default value is True.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For create_watersheds, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional. The
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the estimated number of credits required to run the operation will be returned.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
:returns result_layer :
FeatureLayerif output_name is specified, elseFeatureCollection.USAGE EXAMPLE: To create watersheds for Chennai lakes. lakes_watershed = create_watersheds(lakes_lyr, search_distance=3, search_units='Kilometers', source_database='90m', output_name='create watersheds')
trace_downstream¶
-
arcgis.features.find_locations.trace_downstream(input_layer, split_distance=None, split_units='Kilometers', max_distance=None, max_distance_units='Kilometers', bounding_polygon_layer=None, source_database=None, generalize=True, output_name=None, context=None, gis=None, estimate=False, future=False)¶ 
The
trace_downstreammethod determines the trace, or flow path, in a downstream direction from the points in your analysis layer.For example, suppose you have point features representing sources of contamination and you want to determine where in your study area the contamination will flow. You can use
trace_downstreamto identify the path the contamination will take. This trace can also be divided into individual line segments by specifying a distance value and units. The line being returned can be the total length of the flow path, a specified maximum trace length, or clipped to area features such as your study area. In many cases, if the total length of the trace path is returned, it will be from the source all the way to the ocean.Parameter
Description
input_layer
Required feature layer. The point features used for the starting location of a downstream trace. See Feature Input.
split_distance
Optional float. The trace line will be split into multiple lines where each line is of the specified length. The resulting trace will have multiple line segments, each with fields FromDistance and ToDistance.
split_units
Optional string. The units used to specify split distance.
Choice list: [‘Meters’, ‘Kilometers’, ‘Feet’ ‘Yards’, ‘Miles’].
The default is Kilometers.
max_distance
Optional float. Determines the total length of the line that will be returned. If you provide a bounding_polygon_layer to clip the trace, the result will be clipped to the features in that layer regardless of the distance you enter here.
max_distance_units
Optional string. The units used to specify maximum distance.
Choice list: [‘Meters’, ‘Kilometers’, ‘Feet’ ‘Yards’, ‘Miles’].
The default is ‘Kilometers’.
bounding_polygon_layer
Optional feature layer. A polygon layer specifying the area(s) where you want the trace downstreams to be calculated in. For example, if you only want to calculate the trace downstream with in a county polygon, provide a layer containing the county polygon and the resulting trace lines will be clipped to the county boundary. See Feature Input.
source_database
Optional string. Keyword indicating the data source resolution that will be used in the analysis.
Choice list:
Finest: Finest resolution available at each location from all possible data sources.
30m: The hydrologic source was built from 1 arc second - approximately 30 meter resolution, elevation data.
90m: The hydrologic source was built from 3 arc second - approximately 90 meter resolution, elevation data.
The default is Finest.
generalize
Optional boolean. Determines if the output trace downstream lines will be smoothed into simpler lines or conform to the cell edges of the original DEM.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service.If overwrite is True in context, new layer will overwrite existing layer.
If output_name not indicated then new
FeatureCollectioncreated.
context
Optional dict. Additional settings such as processing extent and output spatial reference. For trace_downstream, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+
# Example Usage >>> trace_res = trace_downstream( ... context = { "extent": { "xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{ "wkid":102100, "latestWkid":3857 } }, "outSR": {"wkid": 3857}, "overwrite": True} ... )
gis
Optional. The
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the number of credits to run the operation will be returned.
future
Optional boolean.
If True, a future object will be returned that can be queried for results. The process returns control to the user.
If False, the process waits for results until returning control to the user. The default is False.
- Returns
FeatureLayerifoutput_nameis set, elseFeatureCollection.
# USAGE EXAMPLE: To identify the path the water contamination will take. path = trace_downstream(input_layer=water_source_lyr, split_distance=2, split_units='Miles', max_distance=2, max_distance_units='Miles', source_database='Finest', generalize=True, output_name='trace downstream')